


There’s a working assumption baked into most AEO strategies right now: that LLMs behave like a smarter, chattier version of search. You optimize content, the model surfaces it, buyers find you. The mechanics might be new, but the motion is familiar.
Our research says that assumption is wrong. And it’s wrong in a way that fundamentally changes how you should plan, create, and measure content for AI discovery.
The biggest takeaway from our Dark AI study is a stark difference in how LLMs behave at each stage of the buyer journey. Not subtle differences in tone or formatting. Structural differences in whether the model retrieves your content at all, how many brands it names, how consistently it names them, and what kind of language it uses to frame its response. These aren’t stylistic variations. They’re different operating modes, and they demand different strategies.
Three Stages, Three Entirely Different Machines
Most AEO advice treats “showing up in AI” as a single problem. Our data shows it’s at least three.
We structured prompts across awareness, consideration, and conversion stages, varying specificity, constraints, and stakeholder perspective, then tracked what the models actually did. Not just what they said. What they did: whether they retrieved external content, how many brands they mentioned, how consistently those brands appeared across runs, and what kind of language framed the response.
The differences were not quite stark.
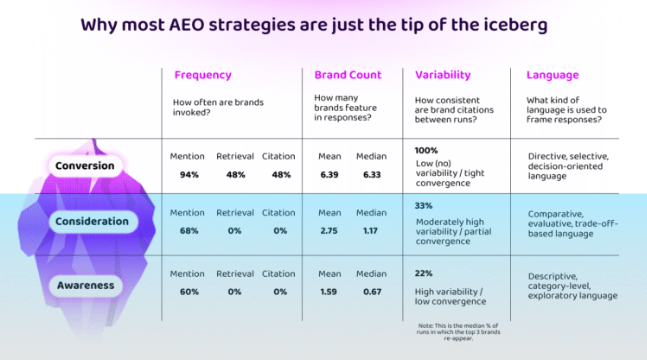
At awareness, the model operates almost entirely from internal knowledge. Brand mentions appear in 60% of responses, but retrieval sits at 0%. Citations: also 0%. The language is descriptive, category-level, exploratory. The model names an average of 1.59 brands per response, and which brands it names changes significantly between runs, only 22% consistency. It’s exploring. Drawing from memory with high variability.
At consideration, things tighten slightly. Brand mentions climb to 68%, but retrieval and citations remain at zero. The model starts comparing approaches, evaluating trade-offs, helping the user build constraints. Brand count rises to a mean of 2.75, and consistency increases to 33%. The shortlist is forming, but it’s still fluid.
At conversion, the model transforms. Brand mentions jump to 94%. Retrieval suddenly appears at 48%. Citations: 48%. The language shifts to directive: “best for,” “recommended,” “top choice.” Brand count surges to a mean of 6.39, and consistency hits 100%. The same top 3 brands surface every single time. The model has converged, and it rarely deviates.
The implication is stark: retrieval and reasoning are selectively invoked based on the task, not as default behaviours. The model doesn’t always go looking for your content. It only does so when the prompt demands a defensible recommendation, which is almost exclusively at conversion.
Convergence: The Mechanism That Changes Everything
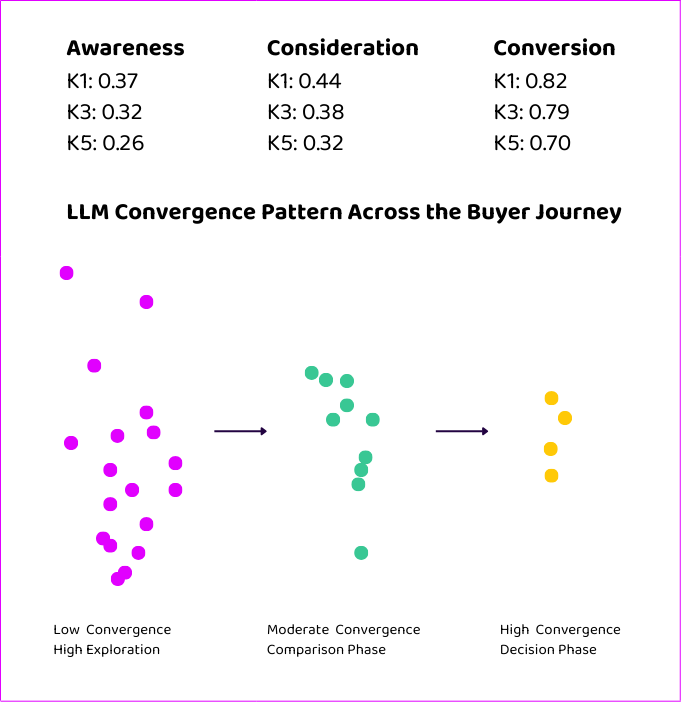
The behavioural shift from exploration to lockdown isn’t random. Our research quantifies it through what we call canon concentration, measured on a 0–1 scale using K1, K3, and K5 scores that track how tightly the model consolidates around its top-recommended brands.
At awareness, K1 concentration is 0.37. The model spreads its attention across a broad, loosely defined set of options. At consideration, K1 rises to 0.44: partial convergence, with the model beginning to cluster around preferred options but still open to variation. At conversion, K1 hits 0.82. The option pool has collapsed. The model consolidates to a few high-credibility brands and rarely deviates.
This is convergence. And it explains something that should trouble anyone building an AEO strategy around citation counts: 84% of all AI prompts produce no brand citations whatsoever. Citations are not a general-purpose signal. They’re a BOFU-specific behaviour triggered when the model needs to justify a recommendation. At awareness and consideration, where buyers are learning, framing problems, and building requirements, the citation rate is literally zero.
“Intent-Matching” and Why Recommendations can be Misleading
When the model reaches conversion, it doesn’t just name brands more consistently. It uses language that sounds like endorsement: “best for enterprise teams,” “recommended for mid-market,” “top choice for integration-heavy workflows.” This language feels like the model is expressing a preference. It’s tempting to track it, chart it, and report it upward as proof that your AEO strategy is working.
This shift should not be mistaken for preference or endorsement. Our research shows that directive BOFU language reflects the model returning a conclusive answer inside a constrained option space. It’s intent-matching, not brand advocacy. LLMs are trained to provide the best answer possible. Where the prompt’s intent requires a definitive, decision-oriented response, thats what it gives you.
The model is doing what the prompt asks (make a recommendation) within the narrow set of brands that survived convergence. The “top choice” framing is a task behavior, not a verdict on your content or product quality.
This matters enormously for measurement. Sentiment analysis on post-convergence queries is a deeply misleading metric. You’re reading positive language that’s structurally guaranteed by the prompt type, not earned by your content’s influence. The brands in the converged set will all receive directive, positive framing, because that’s what the model does at this stage.
Two Different Jobs: Influence Upstream, Survive Downstream
If LLMs behave as three different machines across the journey, your AEO strategy needs distinct objectives at each stage. Our research frames these as sequential: influence comparison and problem framing upstream, then survive convergence downstream.
The upstream job, awareness and consideration, is about shaping how the model explains the problem space, what attributes it treats as important, and how it frames trade-offs between approaches. This is where your content has the most leverage, because the model is drawing from internal knowledge with high variability. The option space is still being defined. Comparative framing is, as our data shows, most influential before convergence occurs.
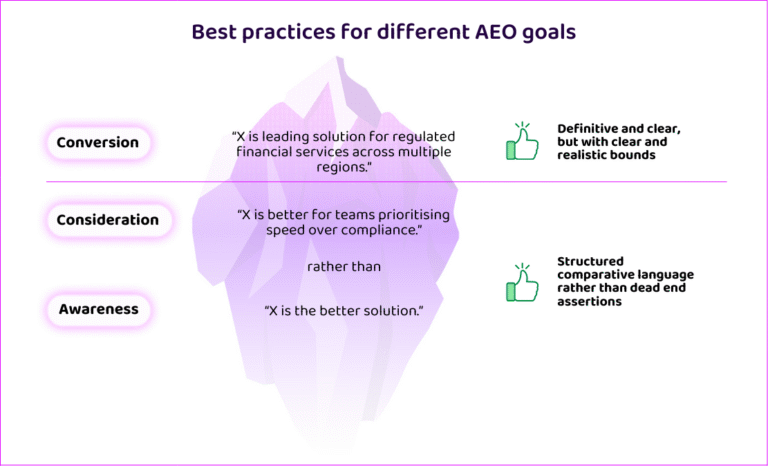
The content posture here is nuance and balance. Structured comparative language. Honest trade-off framing. Category education that helps the model build the right constraints. Self-assertive or absolute positioning (“we’re the best overall”) is actually counterproductive at this stage, where the model rewards specificity and balance over dominance claims.
The downstream job, conversion, is different. The option pool has already narrowed. Your objective is to remain inside the converged set as constraints get applied. The content posture shifts to definitive and clear, but within realistic bounds. Specificity builds confidence.
Why This Breaks the Current Playbook
The prevailing AEO approach treats AI optimization as a single motion: track mentions, count citations, optimize to rank. This mirrors the SEO playbook, but builds on the incorrect assumption that the system behaves consistently regardless of where the buyer is in their journey.
Our data shows it doesn’t.
If you chase citations, you’re optimizing for the one stage where the model is least influenceable, where convergence is tightest and the option pool is already locked. If you treat directive BOFU language as proof of preference, you’re misreading task behaviour as a brand signal. If you build your tracked prompt lists by scraping your own site, you’re selecting for conversations where you already appear and missing the upstream framing conversations where influence actually forms.
The funnel is no longer a useful visualisation for understanding how LLMs interact with your content. We prefer the iceberg: the visible tip (citations, referral traffic, consistent brand mentions) represents only the conversion layer. Below the surface is where problems get framed, criteria get built, and category narratives get shaped. That’s where most of the influence happens. And it’s almost entirely invisible to the metrics most teams are currently tracking.
What to Do With This
The shift requires rethinking how you plan content:
- Treat AEO as three distinct problems with different objectives, content postures, and success metrics at each stage.
- Upstream (awareness/consideration): create content that shapes comparison criteria and problem framing. Use structured, balanced comparative language. Don’t optimize for citations here. There are none.
- Downstream (conversion): be definitive within clear, bounded use cases. Make your claims specific, defensible, and easy to retrieve. Avoid broad superiority claims.
- Measure upstream, not just downstream: Track inclusion before convergence. Track criteria alignment. Stop treating BOFU citation counts as your north star.
The full study and breakdown of convergence, Dark AI and how to measure and influence it are in our Dark AI report.
The brands that win in AEO will be the ones that understand how the model behaves and thinks beyond existing SEO-centric frameworks to influence it in a way that reflects that behaviour.
